Research Ideas for the Facebook Hateful Memes Challenge
 Hateful Memes Challenge @ NeurIPS 2020
Hateful Memes Challenge @ NeurIPS 2020Virtual
Talk Overview
This talk was presented at the Hateful Memes Challenge session @ NeurIPS 2020 as a contributed talk.
Key Research Ideas
Object Detection based Image Captioning: Using image captioning to introduce outside world knowledge and find deeper relationships between text and image modalities.
Sentiment Analysis on Both Modalities: Including high-level features like text and image sentiments to enrich the multimodal representations.
Related Project
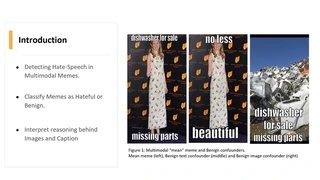
This talk is based on our project Detecting Hate Speech in Multi-modal Memes.

I’m a Senior Applied Scientist at Microsoft, building multimodal query recommendation systems for Bing Image Search. I work at the intersection of computer vision and language, turning modern ML into reliable, high-impact product experiences.
I’m interested in VLMs, multimodal retrieval, and recommender systems. If you’re building in multimodal AI, I’m happy to chat - especially around 0→1 prototypes and productionizing models.